スクレイピングツールを作成してみた
2026.01.27

ホームページから情報を拾おうとしたときに
使う技術がスクレイピングですが、
一般的なPythonあたりでやると、BeautifulSoupが定番。
しかし意外とかゆいところに手が届かないことが多くて悩むことが多い。
一番の問題が速度問題。
htmlソースのリード時間の殆どは通信速度に依存するため、
この部分はどうしようもないとしても、
解析に時間が掛かるのは納得がいかない。
Delphiのみでやってみると、望むとおりの結果はだせるが、
速度がやはり物足りない。
最適解はなんだと検討した結果、
スクレイピングエンジンはC言語で作って、
抽出結果を多言語で取り扱うように決めた。
作成は結構手間取ったが思い通りのものができたので大変満足。
実行ファイル名は、scrape.exe
スクレイピングしたいURLをurl.txtに書いておく。(現状は1アドレスのみ)
抽出したい箇所のXpathをXpath.Txtへ(何レコードでも可能)
抽出結果はout.txtにCSVで吐き出される。
各ファイル名を変更したい場合はコマンドラインに-fオプションを指定すれば可能。
第1引数がUrlファイル名、第2引数がXpathファイル名、第3引数が出力ファイル名になる。
例としては、
Scrape.exe -f a.txt b.txt c.txt
抽出したデータの空白を取り除きたいときは -t オプションをつけるといい。
scrape.exeを立ち上げる時にメモリのロードに時間がとられるが、
それが煩わしい場合は、事前に起動してメモリに常駐するモードも用意した。
-w で事前に立ち上げて置き、
プログラムからパイプで接続するだけでいい。とても快適だ(;´Д`)
ただし、エラーが出たら毎回警告がでるのでは完全自動化にすることができないので
-q オプションでエラー表示をしないというものも付けた。
Javascriptで表示されるページの情報が欲しい場合、
動作は遅いが、-jで取りに行けるようにもしてある。
常駐モードは処理が速い。快適、快適。望む通りの速度が出ている。
単体でテキストファイル(CSV)が吐き出される形にしたので、
Excelで直接開くことも可能だ。もちろんAccessのデータベースに貯めることもできる。
応用の幅は広い。
スクレイピングの対象であるホームページが改変されたとしても、
Xpath.txtの内容を書き換えるだけでいいので、
プログラムのコードは一切いじる必要がない。
このツールができたことで、スクレイピングのプログラムを作るたびに
毎回似たようなコードを書く必要もなくなった。
ここ最近でもっとも効率化がすすんだ部分だと思う。
 2026.01.27 01:59
|
2026.01.27 01:59
| 



Delphiでフォームに張り付けたコンポーネントの色が変
2024.01.21
最近はガチのプログラム開発が無いので、
DelphiのCommunity Editionを使ってお茶を濁しているのですが、
Delphi11からフォームに張り付けたコンポーネントの色がおかしいことに気が付きました。
旧バージョンで動かすと問題ありません。
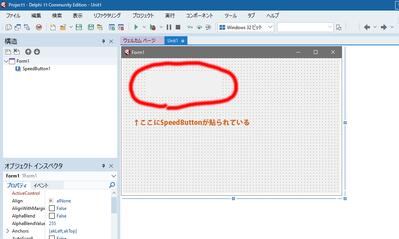
上の写真を見てもらえばわかると思いますが、
SpeedButtonにしてもちゃんと表示されていません。
はて、これは仕様なのか、バグなのか。
詳細はわかりませんが、設定で直ります。
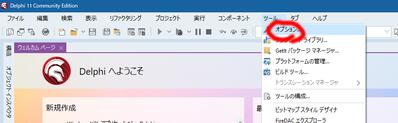
ツールのオプションを開きます。
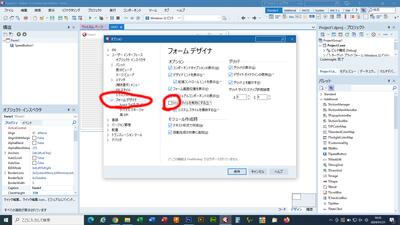
ウインドウが新たに表示されますが、その中のフォームデザイナで、
VCLスタイルを有効にするに入っているチェックを外します。
その後保存して終了
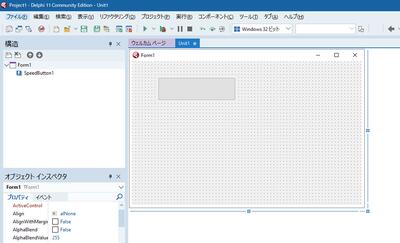
これで正常に表示されるようになりました。
DelphiのCommunity Editionを使ってお茶を濁しているのですが、
Delphi11からフォームに張り付けたコンポーネントの色がおかしいことに気が付きました。
旧バージョンで動かすと問題ありません。
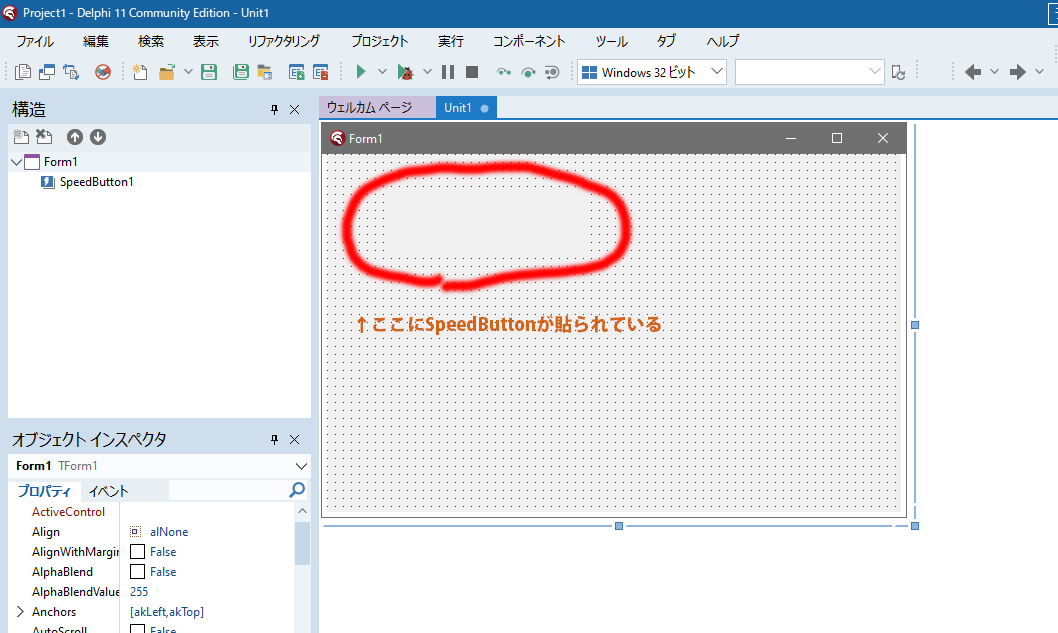
上の写真を見てもらえばわかると思いますが、
SpeedButtonにしてもちゃんと表示されていません。
はて、これは仕様なのか、バグなのか。
詳細はわかりませんが、設定で直ります。
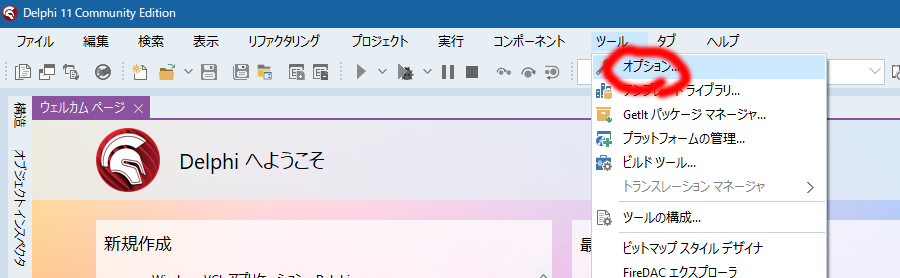
ツールのオプションを開きます。
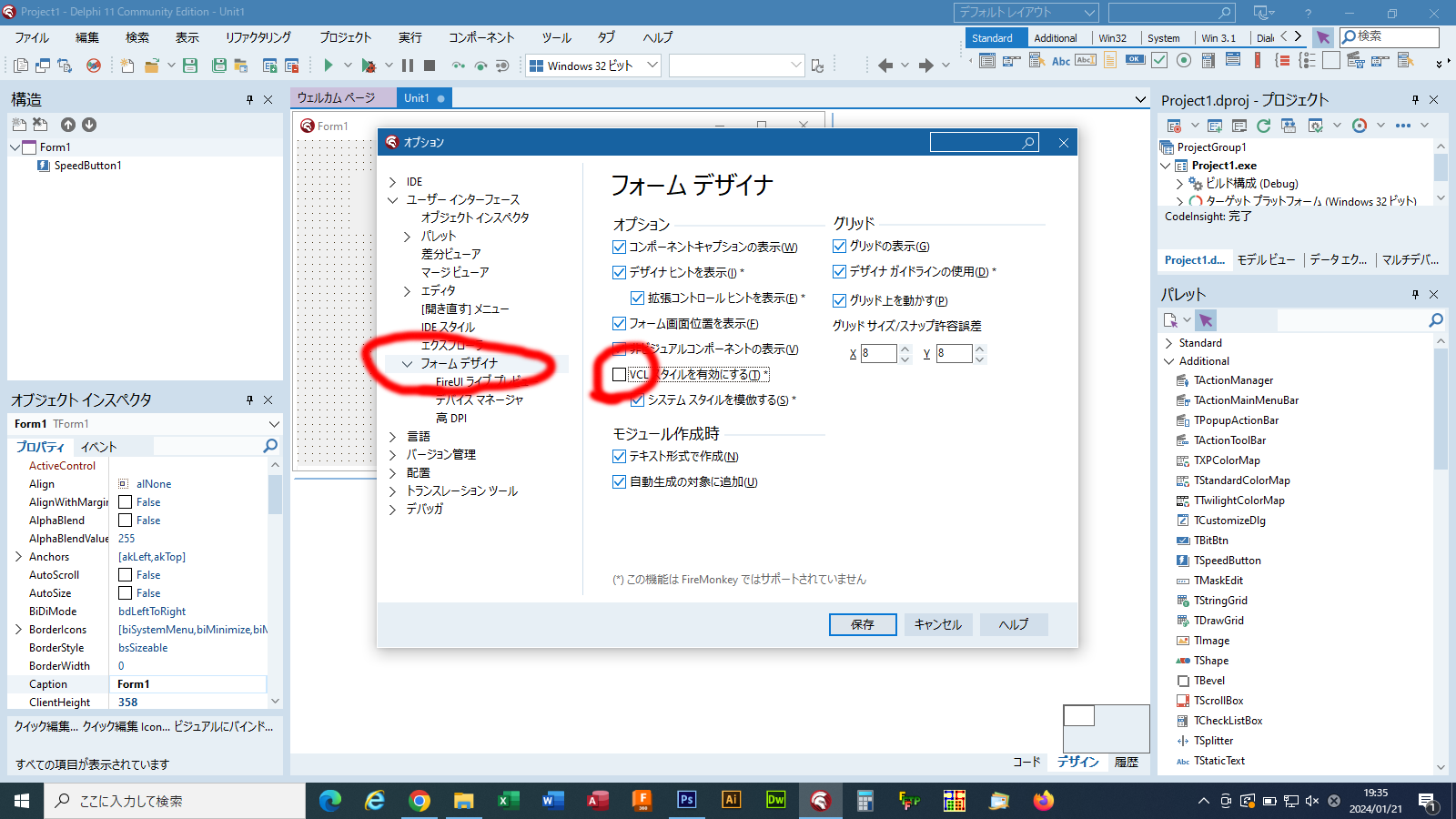
ウインドウが新たに表示されますが、その中のフォームデザイナで、
VCLスタイルを有効にするに入っているチェックを外します。
その後保存して終了
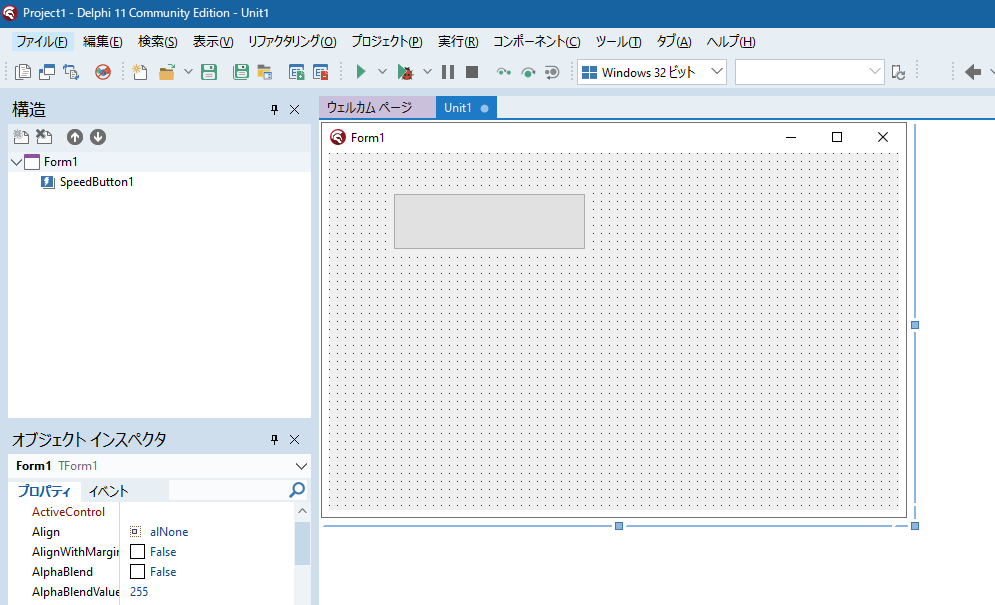
これで正常に表示されるようになりました。
【Python】スクレイピングしたあとのデータ保存
2023.07.05
うまくいかないグチです(;´Д`)
年のせいか物覚えと理解力の低下が著しいです・・
スクレイピングといえば、Rubyか、Pythonが流行りと聞いて
どうせならとPythonでSeleniumとBeautiful Soupを試してます。
私の得意言語、Delphiで出来ればいいのだけどいいライブラリが無いのでね仕方ないね(;´Д`)
試してみて思ったこと・・・
Pythonでも1つで完璧にこなすのは無理なのね(;´Д`)
Seleniumはブラウザのバージョンと合致したドライバーを持っていないと使えない弱点があり、
動作も遅い。
しかし最近はJava Scriptを通さないと重要な部分は見せないページが増えてきたので、
Seleniumの機能が無いと始まらない(;´Д`)
Beautiful Soupは軽快且つ単独でHTMLを読みにいき
解析を行ったあとに対して検索を行うので
ドライバーがいらない快適性があるも、
Xpathに対応してないので、
裏技的にlxmlで変換してからなんて面倒なことをする・・
素人にはこれがストレス極まりない(;´Д`)
そして、SeleniumとBeautiful Soupどちらをうまく使っても
XPATHで拾えないデータが結構出てくる。
もちろんCSSセレクタ使ってもダメ・・・
これがまたストレス(;´Д`)
データを捨てるわけにもいかないので、
階層を一つ上げて全部を吸い上げ、コードでゴリゴリ分解とか
ホームページの仕様変更に耐性が弱すぎるので
信用に値しないものを作る意味は?と考え込む・・
そして拾ったデータを整理し2次元配列に仕舞い込んで
最後、CSV出力しようと思ったときにもうまくいかないで躓く・・・
慣れない言語をあつかうときの窮屈感たるや吐き気を催すレベル(;´Д`)
とりあえず、一般的なCSV吐き出しで使われる
csv.writer(出力ファイル)
と私は相性が悪いらしい・・・・
delimiterとquotecharを設定してもうまく機能しない・・・
空白が文字コード化されて保存されたり面倒くさい事件が多く起きる。
しかもカンマで区切ってほしいのにスペースでも区切ってしまう現象もおきて
文字列がコマ切れ状態に(;´Д`)
これについては解決策を見つけることができて、
煩わしいことをきれいに全部解決してくれたpandasに拍手。
import pandas as pd
columns = ["date", "serial", "name", "tanka", "kosu", "kingaku"]
df = pd.DataFrame(配列 , columns=columns)
df.to_csv('d:\output.csv' , index=False, encoding="shift_jis")
これだけで配列があっさりCSVファイルを出力できるのでコードもすっきり。
項目名がいらないのならさらに1行消せる。大満足(;´Д`)
しかしXPathもCSSセレクタでも拾えないデータはどうしようか・・・
ある意味これが対策されているってことなんだと思うけど、
正規表現でなら正確に抜け出せるのだろうか・・
1つ1つ解決していくのにえらい時間かかる。
まだまだ迷走中(;´Д`)
年のせいか物覚えと理解力の低下が著しいです・・
スクレイピングといえば、Rubyか、Pythonが流行りと聞いて
どうせならとPythonでSeleniumとBeautiful Soupを試してます。
私の得意言語、Delphiで出来ればいいのだけどいいライブラリが無いのでね仕方ないね(;´Д`)
試してみて思ったこと・・・
Pythonでも1つで完璧にこなすのは無理なのね(;´Д`)
Seleniumはブラウザのバージョンと合致したドライバーを持っていないと使えない弱点があり、
動作も遅い。
しかし最近はJava Scriptを通さないと重要な部分は見せないページが増えてきたので、
Seleniumの機能が無いと始まらない(;´Д`)
Beautiful Soupは軽快且つ単独でHTMLを読みにいき
解析を行ったあとに対して検索を行うので
ドライバーがいらない快適性があるも、
Xpathに対応してないので、
裏技的にlxmlで変換してからなんて面倒なことをする・・
素人にはこれがストレス極まりない(;´Д`)
そして、SeleniumとBeautiful Soupどちらをうまく使っても
XPATHで拾えないデータが結構出てくる。
もちろんCSSセレクタ使ってもダメ・・・
これがまたストレス(;´Д`)
データを捨てるわけにもいかないので、
階層を一つ上げて全部を吸い上げ、コードでゴリゴリ分解とか
ホームページの仕様変更に耐性が弱すぎるので
信用に値しないものを作る意味は?と考え込む・・
そして拾ったデータを整理し2次元配列に仕舞い込んで
最後、CSV出力しようと思ったときにもうまくいかないで躓く・・・
慣れない言語をあつかうときの窮屈感たるや吐き気を催すレベル(;´Д`)
とりあえず、一般的なCSV吐き出しで使われる
csv.writer(出力ファイル)
と私は相性が悪いらしい・・・・
delimiterとquotecharを設定してもうまく機能しない・・・
空白が文字コード化されて保存されたり面倒くさい事件が多く起きる。
しかもカンマで区切ってほしいのにスペースでも区切ってしまう現象もおきて
文字列がコマ切れ状態に(;´Д`)
これについては解決策を見つけることができて、
煩わしいことをきれいに全部解決してくれたpandasに拍手。
import pandas as pd
columns = ["date", "serial", "name", "tanka", "kosu", "kingaku"]
df = pd.DataFrame(配列 , columns=columns)
df.to_csv('d:\output.csv' , index=False, encoding="shift_jis")
これだけで配列があっさりCSVファイルを出力できるのでコードもすっきり。
項目名がいらないのならさらに1行消せる。大満足(;´Д`)
しかしXPathもCSSセレクタでも拾えないデータはどうしようか・・・
ある意味これが対策されているってことなんだと思うけど、
正規表現でなら正確に抜け出せるのだろうか・・
1つ1つ解決していくのにえらい時間かかる。
まだまだ迷走中(;´Д`)
【Python】 ドハマリselenium サンプルコードが動かない
2023.06.12
PythonとSelenium、Beautiful Soupの組み合わせでスクレイピングの勉強をしていますが、
ネットで転がっているサンプルコードでエラーがでる。
というかほとんどすべてがダメ(;´Д`)
どうやら最近登場したseleniumのバージョン4が問題らしい。
そりゃぁ、インストールするときはその時の最新バージョン入れちゃうよね。
まさか従来のソースが使えなくなるなんて考えてもみなかったよ(;´Д`)
driver.findElementByClassName("******");
driver.findElementByCssSelector(".******");
driver.findElementById("******");
driver.findElementByLinkText("******");
driver.findElementByName("******");
driver.findElementByPartialLinkText("******");
driver.findElementByTagName("******");
driver.findElementByXPath("******");
ここら辺の類が全部ダメ。もちろん複数形もダメ。
なんか表記方法の仕様変更らしい。勘弁してくれ(;´Д`)
driver.findElement(By.className("******"));
driver.findElement(By.cssSelector(".******"));
driver.findElement(By.id("******"));
driver.findElement(By.linkText("******"));
driver.findElement(By.name("******"));
driver.findElement(By.partialLinkText("******"));
driver.findElement(By.tagName("******"));
driver.findElement(By.xpath("******"));
こんな感じにそれぞれが変更になった。
私はカッコが複数絡み合うのは見にくいのだが・・・
あと操作系は
クリック element.click()
テキスト入力 element.send_keys("********")
キー入力 element.clear()
値のクリア element.submit()
テキスト取得 element.text
のように各エレメントに対して.で接続する。
うーーん、これから読み進める書籍がとてもめんどくさいことに(;´Д`)
ネットで転がっているサンプルコードでエラーがでる。
というかほとんどすべてがダメ(;´Д`)
どうやら最近登場したseleniumのバージョン4が問題らしい。
そりゃぁ、インストールするときはその時の最新バージョン入れちゃうよね。
まさか従来のソースが使えなくなるなんて考えてもみなかったよ(;´Д`)
driver.findElementByClassName("******");
driver.findElementByCssSelector(".******");
driver.findElementById("******");
driver.findElementByLinkText("******");
driver.findElementByName("******");
driver.findElementByPartialLinkText("******");
driver.findElementByTagName("******");
driver.findElementByXPath("******");
ここら辺の類が全部ダメ。もちろん複数形もダメ。
なんか表記方法の仕様変更らしい。勘弁してくれ(;´Д`)
driver.findElement(By.className("******"));
driver.findElement(By.cssSelector(".******"));
driver.findElement(By.id("******"));
driver.findElement(By.linkText("******"));
driver.findElement(By.name("******"));
driver.findElement(By.partialLinkText("******"));
driver.findElement(By.tagName("******"));
driver.findElement(By.xpath("******"));
こんな感じにそれぞれが変更になった。
私はカッコが複数絡み合うのは見にくいのだが・・・
あと操作系は
クリック element.click()
テキスト入力 element.send_keys("********")
キー入力 element.clear()
値のクリア element.submit()
テキスト取得 element.text
のように各エレメントに対して.で接続する。
うーーん、これから読み進める書籍がとてもめんどくさいことに(;´Д`)





